
生成AIは社内活用に非常に便利であり、情シスや総務、人事などの部門に寄せられる「問い合わせ」対応の効率化や社内のナレッジ(社内に蓄積されたノウハウや業務プロセス、知識などの有益な情報のこと)の効果的な共有に役立ちます。
しかし、多くの企業が直面するのが「AIを導入したが、期待した回答が得られない」という壁です。
この原因の一つとして読み込ませているデータの質が低いということが挙げられます。
AIの品質に目を向けてしまいがちですが実際にはAIモデルの性能の問題ではなく、データの品質改善によってAIの回答精度の向上が見込まれます。
本記事では、AI活用を成功させるための基盤となる社内データ整理の重要性と、実践のコツを解説します。
社内データ整理とは、企業内に散在しているマニュアル、議事録、顧客対応履歴、技術仕様書、各種ファイルなどの情報を、即座に活用できる状態に整えるプロセスを指します。
単にファイルをフォルダに分けることではなく、データの重複を排除や最新化などを行い検索性を高めるための情報の構造化がここでいうデータ整理の本質です。
これまでのデータ整理はフォルダ内のファイルを整理するなどの「人間が検索して見つけやすくすること」がなんとなくゴールになっていたかと思います。
しかし、生成AIの導入が進む現在では、AIが誤解なくコンテキスト(文脈)を読み取れることが新たなゴールとなっています。
つまり、社内データ整理は人間だけでなくAIが理解しやすい形に整理するということになります。
生成AIの仕組みにおいて、社内データはAIが学習する元データとなります。データが整理されていない状態でAIを導入することは、誤った知識を学習させることと同義です。
ここでは、なぜデータ整理が不可欠なのか、その理由を2つのポイントに整理して解説します。
データ分析やAIの世界には「Garbage In, Garbage Out(ゴミを入れればゴミが出る)」という有名な原則があります。AIのアルゴリズムがどれほど優秀でも、インプット(社内データ)が低品質であれば、アウトプットも低品質になります。
内容が重複していたり、関係のない無駄な記述が多かったり、はたまた古いデータと新しいデータが混在していたりするとAIは適切な情報を見つけにくくなります。
極端な例だと、古いマニュアルだけが読み込まれておりAIがその内容を学習していた場合は当然出力内容も誤ったものとなります。
したがって、正しくて新しいデータをインプットすることが大切になります。
生成AIの課題の一つに、事実に基づかない情報を生成してしまう「ハルシネーション」があります。ハルシネーションの原因は複数ありますが、読み込ませたデータの中に「正解」と「古い情報」が混在している場合、どちらが正しいかを自力で判断できないことが多々あります。
データ整理を行い、データの品質を向上させることで、AIが参照する情報の真実性が高まります。
結果的にハルシネーションを抑制することにつながり、実務でAIを利用する上で必要な精度を担保しやすくなります。
AI活用を前提としたデータ整理は、以下のステップで進めるのが効率的です。
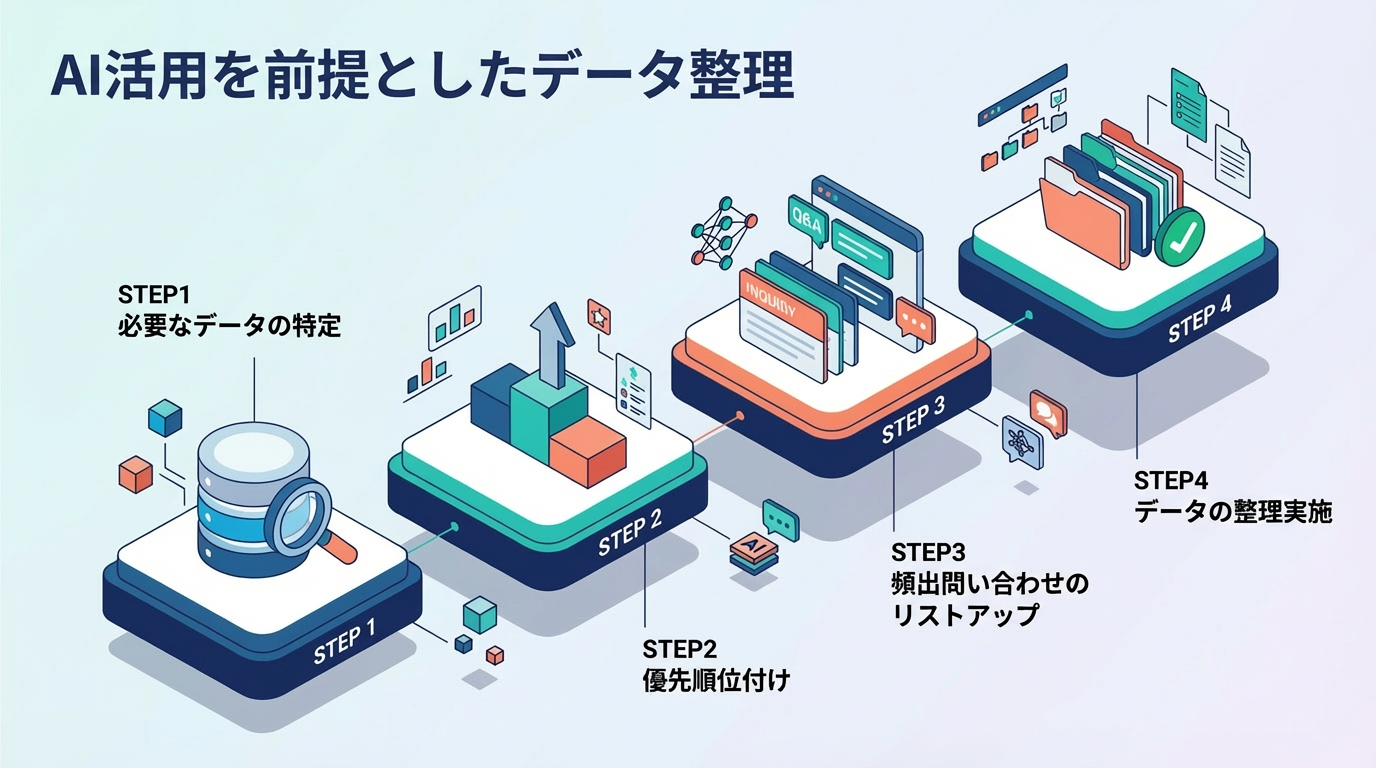
まずは、どの業務をAI化したいのかを明確にしましょう。例えば情シス部門でのIT周りの問い合わせをAI化したいといった場合には情シス部門が管轄している情報のデータが必要になってきます。
一度に多くの業務をAI化しようとするとその分必要なデータの範囲も広くなるため、対象範囲を小さく始めるのが良いでしょう。
必要なデータの範囲が特定できたら、どの範囲から優先的に着手すべきかを見極めましょう。
データの中から、「利用頻度が高いもの」かつ「情報の鮮度が重要なもの」から順に整理の優先順位を付けます。まずはスモールスタートで、特定の業務範囲のデータから着手するのがおすすめです。
続いて、具体的な頻出問い合わせのリストアップを行います。
AIチャットボット等の導入、もしくは構築する場合、実際に現場で発生しているよくある質問をリスト化することが必要です。
現場の負債(工数)となっている部分を特定することで、整理すべきデータが何なのかが見えてきます。
リストアップする段階では、直近1~2ヶ月で多かった問い合わせ内容の確認や、チーム内でミーティングを行なって頻出問い合わせの棚卸をするのが有効です。
頻出問い合わせが用意できたら、いよいよデータの整理を行いましょう。
問い合わせの回答内容データとなるマニュアルやファイルを洗い出して内容を整理していきます。
整理する際は、下記の内容を実施していきます。
類似したマニュアルやファイルは一つに統合する:
バージョン違いや似た内容のファイルが散在していると、AIが混乱します。最新の正解データを一つにまとめ、古いものはアーカイブしましょう。
古い内容や誤りは削除する:
「2022年版」「旧規定」といった古い情報はAIの精度を下げるノイズです。これらを排除し、情報の正誤を明確にしましょう。
検索されるようなキーワードを盛り込む:
AI導入後に従業員が検索しやすいよう、マニュアル内に適切な見出しやキーワードを配置します。専門用語だけでなく、初心者が検索しそうな「話し言葉に近いキーワード」も含めると、AIのヒット率が高まります。
このようにして、データを整理していくことでAI活用を開始した後も比較的満足な結果を得やすくなります。
データ整理は、なかなか骨の折れる作業です。一度の作業で終わりではなく、継続的に行うものであると心得ておくのが良いでしょう。
日々の業務を進めていくにつれデータの内容自体を更新しなければならなくなることもあるかと思います。その場合は都度、時間を設けてマニュアルやファイルの内容を更新しましょう。
また、AI活用を小さくはじめて運用が回り出したら少しずつ活用範囲を広げていきます。
その際もまた同様にデータの整理を行なっていきます。
日頃からデータ更新の実施をチーム内の業務として共通認識を作っておくのがおすすめです。
生成AIを活用し、実際の業務で効果を発揮するには、整えられた良質な社内データが必要です。
ぜひデータ整理をできるところからはじめてみてください。
社内データを活用し、問い合わせ管理業務や社内ナレッジの管理を効率化するならhelpmeee! KEIKOがおすすめです。
まずはお気軽に資料ダウンロード!
.png)





.avif)
